This week, I wrote a few programs solving the task of this week’s Weekly Challenge. I already explained the solution in the Raku programming language. In this post, I’d like to demonstrate other solutions. The key point is that they not only use different programming language but also approach the problem differently and implement different algorithms. And that’s the most interesting part.
Let me briefly remind the task and the solution in Raku. If you already have read my previous post, you can skip directly to the C++ solution. The solutions are given in the order of their creation.
Task: Lonely X
You are given m x n character matrix consists of O and X only. Write a script to count the total number of X surrounded by Os only.
To illustrate the task, here is the picture where you can clearly see that there are only Os around the lonely Xs.

Solution in Raku
My solution in the Raku programming language is the following:
my @matrix =
< O O X >,
< X O O >,
< X O O >; # square matrix
my @neighbours = ([X] (-1, 0, 1) xx 2).grep(*.all != 0);
for ^@matrix X ^@matrix -> @coord {
next if @matrix[@coord[0]][@coord[1]] eq 'O';
@coord.put
if all(
(@neighbours.map(* <<+>> @coord)).
grep(0 <= *.all <= @matrix.end).
map({
@matrix[$_[0]][$_[1]] eq 'O';
})
);
}
The program prints 0 2, which are the coordinates of the only lonely X found in the given matrix. As this was the first solution, I allowed myself to simplify the task: the matrix here is assumed to be square.
The top-level idea in this program is to scan all cells of the matrix, and for each of them, look around to see the neighbours. There can be maximum 8 neighbours, but for the Xs on the sides or in the corners, not all neighbours exist. The real neighbours are grepped with the obvious condition that their coordinates do not take us outside of the matrix: grep(0 <= *.all <= @matrix.end).
Apart, I have the relative coordinates @neighbours of all potential neighbouring cells, which I add to the coordinates of the current cell in the main loop: @neighbours.map(* <<+>> @coord). Then, I look if all of the neighbours contain Os, and if so, I print the coordinates of the current cell.
The main ingredients in this solution are the high-level routines such as map, grep, or cross- and reduction operators: X, [X].
Solution in C++
The C++ solution is, probably, the most straightforward classical approach but I added an optimisation which I find an interesting thing to mention.
Let me first show the whole solution.
#include <iostream>
#include <vector>
using namespace std;
vector<int> test_move(vector<vector<char>> matrix,
vector<int> current, vector<int> shift) {
current[0] += shift[0];
current[1] += shift[1];
if (current[0] < 0 || current[0] >= matrix.size() ||
current[1] < 0 || current[1] >= matrix[0].size()) {
return vector<int>();
}
else {
return current;
}
}
int main() {
vector<vector<char>> matrix = {
{'O', 'O', 'O', 'X'},
{'O', 'X', 'O', 'O'},
{'O', 'O', 'O', 'X'}
};
vector<vector<int>> neighbours =
{{1, 0}, {-1, 0}, {0, 1}, {0, -1}, {1, 1}, {1, -1}, {-1, 1}, {-1, -1}};
for (auto row = 0; row != matrix.size(); row++) {
for (auto col = 0; col != matrix[0].size(); col++) {
if (matrix[row][col] == 'O') continue;
bool ok = true;
for (auto neighbour : neighbours) {
auto move =
test_move(matrix, vector<int>{row, col}, neighbour);
if (move.empty()) continue;
if (matrix[move[0]][move[1]] == 'X') {
ok = false;
break;
}
}
if (ok) cout << row << ", " << col << endl;
}
}
}
First of all, there’s no restriction on the shape of the matrix. It can be square or rectangular.
The program uses some features of the recent C++ standards, so compile it with the -std=c++17 flag.
In the main function, there are two nested loops to scan the matrix and touch every cell. If the current cell is O, try the next one. Otherwise, test all the neighbours. I made a separate function test_move which gets the coordinates of the current cell and the relative position of the neighbour. This function either returns the absolute coordinates of the neighbour or—if it does not exist—an empty vector.
The rest is simple. If the neighbour contains X, we can stop here and state that the X in the current cell is not a lonely one. If we managed to visit all existing neighbours and found no Xs there, the current X is lonenly, so we print its coordinates.
A better C++ solution
The previous solution is good, but it can be made a little bit more efficient if you have many Xs as neighbours (of course, for such small matrices you will never notice any difference in the efficiency of a C++ program).
The idea is to replace already seen neighbouring Xs with Ys. What does it give us? Imagine you have an X1 in the top left corner of the matrix, and another X2 at the first position of the first row. When you scan the matrix and test the neighbours of the first corner X1, you also visit X2. They are neighbours for each other, so neither of them can be called a lonely X. We can replace X2 with Y so that we immediately skip it when the main loop reaches that cell.
The changes touches the comparisons with 'O' and 'X', and includes an extra assignment:
matrix[move[0]][move[1]] = 'Y';
For the given example case with corner neighbours, the new solution needs 30 tests while the original program makes 35 tests for the same input data.
vector<vector<char>> matrix = {
{'X', 'O', 'O', 'X'},
{'O', 'O', 'X', 'O'},
{'X', 'O', 'O', 'X'}
};
Examine the code of the modified solution on GitHub.
Functional solution in XML+XSLT
The next solution is really different. The matrix data is saved in the XML file:
<?xml version="1.0"?>
<matrix>
<row>
<item>O</item> <item>X</item> <item>O</item>
</row>
<row>
<item>O</item> <item>O</item> <item>O</item>
</row>
<row>
<item>X</item> <item>O</item> <item>O</item>
</row>
</matrix>
The main program is an XSLT transformation document that describes how to handle the input data to generate the output, which is the list of coordinates of the lonely Xs:
1, 2 3, 1
To run the program, you need an XSLT processor, for example, from the libxslt2 library:
$ xsltproc ch-2.xslt ch-2.xml
The transformation scans all the items by first matching the row nodes and then the items in them:
<?xml version="1.0"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output omit-xml-declaration="yes"/>
<xsl:template match="/matrix">
<xsl:apply-templates select="row"/>
</xsl:template>
<xsl:template match="row">
<xsl:apply-templates select="item"/>
</xsl:template>
. . .
</xsl:stylesheet>
Then, there are two templates for the items. A generic template that matches all items and a specialised one for Xs. Having them both in the same file makes the first template matching only Os, and as it does not contain any body, no output is generated for such cells.
<xsl:template match="item"/>
<xsl:template match="item[text() = 'X']">
. . .
</xsl:template>
Finally, the rule for the cell containing an X:
<xsl:template match="item[text() = 'X']">
<xsl:variable name="row" select="count(../preceding-sibling::*) + 1"/>
<xsl:variable name="col" select="position()"/>
<xsl:variable name="lonely" select="
(not(/matrix/row[$row ]/item[$col - 1])
or /matrix/row[$row ]/item[$col - 1] = 'O') and
(not(/matrix/row[$row ]/item[$col + 1])
or /matrix/row[$row ]/item[$col + 1] = 'O') and
(not(/matrix/row[$row + 1]/item[$col ])
or /matrix/row[$row + 1]/item[$col ] = 'O') and
(not(/matrix/row[$row - 1]/item[$col ])
or /matrix/row[$row - 1]/item[$col ] = 'O') and
(not(/matrix/row[$row + 1]/item[$col + 1])
or /matrix/row[$row + 1]/item[$col + 1] = 'O') and
(not(/matrix/row[$row - 1]/item[$col - 1])
or /matrix/row[$row - 1]/item[$col - 1] = 'O') and
(not(/matrix/row[$row + 1]/item[$col - 1])
or /matrix/row[$row + 1]/item[$col - 1] = 'O') and
(not(/matrix/row[$row - 1]/item[$col + 1])
or /matrix/row[$row - 1]/item[$col + 1] = 'O')
"/>
<xsl:if test="$lonely">
<xsl:value-of select="$row"/>
<xsl:text>, </xsl:text>
<xsl:value-of select="$col"/>
<xsl:text disable-output-escaping="yes"> </xsl:text>
</xsl:if>
</xsl:template>
Here, visiting the neighbours is made via a couple of tests: first, we check if it exists: not(/matrix/row[$row + 1]/item[$col + 1]) and if so, we check its payload: /matrix/row[$row + 1]/item[$col + 1] = 'O'.
The result of 8 such tests is saved in the $lonely variable which is used in a Boolean test before generating the output. Thus, the program prints two coordinates on a line for each lonely X found in the source XML data.
Solution in Python
Let us return to a procedural language and create a solution in Python 3.
matrix = [
['X', 'O', 'O'],
['O', 'O', 'X'],
['X', 'O', 'O'],
]
def is_O_cell(x, y):
if 0 <= x < len(matrix[0]) and 0 <= y < len(matrix):
return matrix[y][x] == 'O'
else:
return True
x_cells = [
[col_i, row_i]
for row_i, row in enumerate(matrix)
for col_i, cell in enumerate(row)
if cell == 'X'
]
for x_cell in x_cells:
x, y = x_cell
if is_O_cell(x , y + 1) and \
is_O_cell(x , y - 1) and \
is_O_cell(x + 1, y ) and \
is_O_cell(x - 1, y ) and \
is_O_cell(x + 1, y + 1) and \
is_O_cell(x + 1, y - 1) and \
is_O_cell(x - 1, y + 1) and \
is_O_cell(x - 1, y - 1):
print(f"Lonely X at position ({x}, {y}).")
In this solution, the is_O_cell(x, y) function checks if the cell at the given position x, y contains an O or is outside of the matrix. In the latter case, it returns True. Instead of rejecting the neighbouring cell, we can just pretend that it is a desired neighbour—the same as the one with O in it.
The key thing in this solution in Python is the way I select the cells with Xs from the given matrix. It uses list comprehension with two nested loops:
x_cells = [
[col_i, row_i]
for row_i, row in enumerate(matrix)
for col_i, cell in enumerate(row)
if cell == 'X'
]
The x_cells variable now contains the coordinates of the cells from which we will visit the neighbours. Visiting neighbours is a Boolean chain of calling is_O_cell around the current X cell.
Solution in HTML+JavaScript
This solution is actually an interactive solution that you can play with in a browser. This is the solution which you can try even if you have no compilers installed.
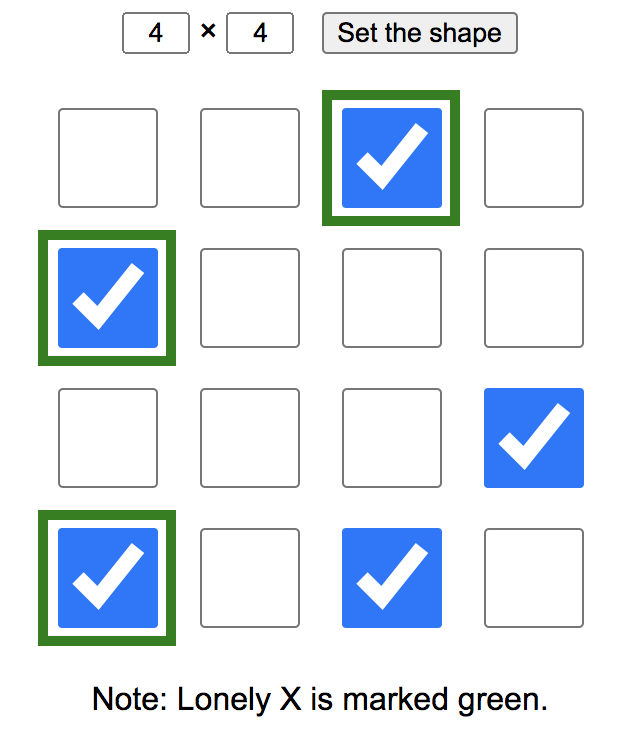
Let me skip the whole code this time and show the main two functions in JavaScript. You can see the rest on GitHub.
Instead of Os and Xs, the content of a cell is represented by the state of the checkbox in it.
When the page loads or when you press the button, the script generates an HTML code for drawing the matrix with checkboxes and necessary data attributes data-x and data-y that keep the coordinates, and the onclick attribute to trigger the function update_lonely() every time you click on a cell.
function update_lonely() {
let cells =
document.getElementById('Shape').getElementsByTagName('input');
let neigbours = [[0, 1], [0, -1], [1, 0],
[-1, 0], [1, 1], [-1, -1],
[1, -1], [-1, 1]];
for (let i = 0; i != cells.length; i++) {
cells[i].parentNode.className = '';
if (!cells[i].checked) continue;
let x = parseInt(cells[i].getAttribute('data-x'));
let y = parseInt(cells[i].getAttribute('data-y'));
let is_ok = true;
for (let c = 0; c != neigbours.length; c++) {
if (!test_cell(x + neigbours[c][0], y + neigbours[c][1])) {
is_ok = false;
break;
}
}
if (is_ok) {
cells[i].parentNode.className = 'lonely';
}
}
}
Here, the neighbours array keeps the relative coordinates of the neighbours as in some of the other programs we saw earlier. Then, we scan the cells and with the help of the test_cell function determine whether the cell is outside of the matrix or its checkbox is not checked, which is equivalent to O in other solutions.
function test_cell(x, y) {
if (x < 0 || y < 0 || x >= w || y >= h) {
return true;
}
else {
let cell =
document.querySelector(
'#Shape tr td input[data-x="'+ x + '"][data-y="' + y + '"]'
);
return !cell.checked;
}
}
In this program, you can see a number of web-specific things such as setting classes to change the visual representation of the result or accessing matrix data using CSS selectors.
Solution in Perl with regular expressions
Do you think there are no more ideas for a fresh solution? There are!
Here is a program in Perl that uses pattern matching to find the lonely Xs.
my @matrix = (
[qw( O O O X )],
[qw( X O O O )],
[qw( O X O X )],
);
for (@matrix) {
unshift @$_, 'O';
push @$_, 'O';
}
unshift @matrix, [map {'O'} 1..scalar(@{$matrix[0]})];
push @matrix, [map {'O'} 1..scalar(@{$matrix[0]})];
my $matrix = join '', map({join '', @$_} @matrix);
my $width = scalar(@{$matrix[0]});
my $gap = '.' x ($width - 3);
my $pattern = "OOO${gap}OXO${gap}OOO";
for my $pos (0 .. length($matrix) - length($pattern)) {
next unless substr($matrix, $pos) =~ /^$pattern/;
my $y = int($pos / $width);
my $x = $pos - $y * $width;
say "$y, $x";
}
Before the main part of the code, we modify the matrix to surround it with Os. So, for the given example, the matrix becomes the following:
O O O O O O O O O O X O O X O O O O O O X O X O O O O O O O
Remember how we returned True for the cells outside of the matrix? Now you can see that this is exactly what happens if you simply extend the matrix and fill it with zeroes that do not change the status of lonely Xs.
The second preparation step is to make a single string out of the matrix:
OOOOOOOOOOXOOXOOOOOOXOXOOOOOOO
Finally, let’s make a regex. What we need is to find an X which is surrounded by Os. Or, in other words, there should be three OOO above and below it, and one O right before and right after. In-between, we can have any characters, which you can express with a series of dots in a regular expression:
my $gap = '.' x ($width - 3);
my $pattern = "OOO${gap}OXO${gap}OOO";
With the given sample matrix, the regex takes the following shape:
OOO...OXO...OOO
The last step is to apply the regex at every position of the $martix string and then convert the linear position to a pair of x and y if the regex matched at that position.
next unless substr($matrix, $pos) =~ /^$pattern/; my $y = int($pos / $width); my $x = $pos - $y * $width;
And that’s it!
* * *
→ GitHub repository
→ Navigation to the Raku challenges post series
One thought on “Programming with passion”