Reini Urban is the author of alternative Perl compilers. In this interview he talks about his work, discusses their internals and shares his thoughts about different approaches to make Perl faster.
Before it all started
How and when did you learn to program?
My father was electrical and mechanical engineer and had a small enterprise with early pre-PC era “computers”. E.g. I played chess via a huge teleprinter machine on ticker tapes. I learned proper programming at high-school on a TRS II and disliked the Apple and Commodore C64. Instead I had a DAI Indata PC, which was an incredible good Z80-based machine with an incremental BASIC compiler.
On university I learned Fortran, Pascal, Prolog and C, but mostly spent my time with Lisp. I studied architecture and became an expert in the CAD system my company worked with. And then I decided to learn the simplier and faster standard system, AutoCAD. I became an expert first in my hometown, I introduced CAD courses in my university. Then via the rise of the internet, I became an AutoLISP authority worldwide. I did lot of Virtual Reality, AI (artificial intelligence) and complicated geometry. The architecture of my boss, Guenter Domenig, was very organic and demanding, but we also had huge projects. I introduced CAD there, and we were very successful. Because of the big and interesting projects I had automatize a lot of planning and drawing steps. Geometric abstractions make very interesting problems. Think for example on geometric 2D pattern matching. Detect a cabinet in a room, and move it to have 10 cm space left to the door. Maintain the plans for a huge university building, 6 floors, 300 m long, the biggest building in Austria. Make it efficient and undercut the planned costs of 1.2 mrd to 800 mill. Programming was only a small part of the successful automation step, but there was also design, planning, communication and execution. Architecture is a much more demanding and generalized job than most engineering jobs. Nevertheless I stopped with archictecture and became an engineer then. Less demanding problems with more free time and double pay. I did civil engineering, city planning, surveying, stage construction, light simulations and everything ended up in movies. Which is my biggest interest since a few decades. Besides surfing.
Programming compilers or VM’s is really much easier then everything else I did before.
What editor do you use?
I started with Multiedit Pro and switched to Emacs and then XEmacs some decades ago. Recently and back to Emacs. But with Visual Lisp, PHP and with Turbo Pascal, the various Borland IDE’s, Symantec C++ and Visual C I had much nicer integrated environments. Without GUI I prefer joe. vi was always a troubling experience with broken termcap settings via unstable telnet lines those days. There was no mosh around.
When and how have you been introduced to Perl?
I needed tools to manage my huge Lisp libraries and programs in the 80’s. I was a big time AutoLISP programmer. Very big.
I wrote my first internationalization tools to maintain German and English versions of my lisp programs in C, disliked awk, but then detected perl4 (people still mixed it up with “Pearl” those days) and switched to perl to maintain those tools. This was in the beginning of the 90’s. perl was a big relevation, and I stopped writing C maintainance code. I only needed to interface external libraries from lisp. I tried to overcome that with an FFI for my lisp’s and emacs. Richard Stallman did not welcome our FFI and Microsoft OLE efforts for emacs, so I switched to xemacs. There was a guy who had more success with this and added an emacs ffi to use GTK. But we were happy with xemacs, and I could use xemacs as AutoCAD, AutoLISP editor until VisualLISP came along. I became the expert in the various AutoLISP compilers, and visited mostly LISP conferences. I think I was the only one who build bridges from a full Common LISP to AutoCAD.
Perl was only a little tool, but I liked the build system and also the help systems I created with pod2rtf. pod2rtf and the perl5.hlp for windows was my first CPAN upload. I created a lot of good documention and webpages with perl for my lisp libraries.
What are other programming languages you enjoy working with?
Lisp and C.
I did professional programming (i.e. sold programs) also in PHP, python, bash, Visual Basic and C. I maintained huge programs in PHP and really like their superior development environment which is almost as good as my previous Visual Lisp environment. It’s a simple stupid language with a lot of early sins, but nowadays it’s much more advanced than perl. Did you check out php7? You should.
What do you think is the strongest Perl advantage?
Brevity, bash compatibility and CPAN.
What do you think is the most important feature of the languages of the future?
The same as in the past. People still don’t manage to get 50% of Common Lisp features. Remember Greenspun’s 10th rule? “Any sufficiently complicated C or Fortran program contains an ad hoc, informally-specified, bug-ridden, slow implementation of half of Common Lisp.” This was 1993, and it still didn’t get any better.
- save-image? perl5 had the beginnings with dump/undump, but nobody caught on.
- Editing live servers via a socket-connected debugger? perldb had remote debugging support, but who uses it? Dancer is pretty close to what we did in the 80’s and 90’s. But still only 30%.
- Macros? There’s mostly only elixir and that’s it. Perl6 macros still have a very quirky syntax.
- Safe and fast async? There’s only haskell, erlang and rust on the horizon. There is safe and there is fast, but mostly not both.
- Numeric tower (precise arithmetic)? Only Common Lisp has fast and precise arithmetic. Well, there is now Julia also. perl6 uses a super-naive and overly slow approach, but at least they acknowledge the importance of not loosing precision when working with numbers. But still Greenspun.
Where do you work? How much time do you spend writing Perl code?
I work now for cPanel maintaining perlcc. They are the only big company using the perl compiler so it’s a natural fit. And cPanel is really an excellent company to work with. I like the American management style, and only in the US engineers are treated properly. The founder still has full control over it, is the best engineer and is an overall fantastic guy.
I work full time and on the weekends when it’s fun, and write mostly C code, and some perl code. The compiler should have been written in C but is only written in perl. This causes problems in the walker, deciding if a B::C internal package is part the compiler or the user program. Maybe I’ll rewrite it in C later.
Should we encourage young people to learn Perl nowadays?
We should encourage people to learn programming. They will not choose Perl.
But interestingly the University in Dresden here still teaches and uses Perl for their linguistic studies. Counting words, verbs, adverbs and such statistical stuff. Science. They sometimes come to our monthly meetings to check their homework problems, and this is fun. I’m reminded to my old days as Lisp teacher at the university.
No, we really should encourage people to learn Lisp and not python or Java or javascript. They are horrible compared to Lisp, and even Perl. Perl is a practical language. People should learn fundamentals. Practice comes over time anyway, and you really should not attend CS classes to learn a practical language, which you can learn in a few days by your own. I learned PHP in 4 days, and perl in about the same time.
If you’re doing web, PHP is still better. Every hoster supports PHP but who supports perl? PHP has a better ecosystem, ruby has nicer frameworks with javascript expertise. For small servers or bridges I mostly used Visual Basic. No libraries, but very easy, very fast, very easy to deploy, nice GUI’s. But for more interesting or more dynamic GUI’s I mostly used perl or python.
In the meantime I switched to use perl in my little Cannes critics website, the only website I’m still maintaining. I was an internet pioneer in Austria with one of the biggest webservers, won a big state award (“Staatspreis”) for our community, was associated with the biggest private internet provider, but don’t maintain web or mail servers anymore. Facebook is perfect enough for me.
But if you need a practical little tool, perl is perfect.
Different perls
What is p2? Is it Perl II?
p2 was my experimental project to come up with a proper VM, after it was clear that parrot failed, and to save the future of perl6 and perl5. They didn’t tell me about the moarvm then, and when they told they aggressively tried to kill parrot with improper attacks on the parrot threading model. So yes, the second perl, a perl reboot on a proper VM, with proper technology. p2 is based on why the lucky stiff’s potion, which is based on the same VM architecture as all the successful VM’s out there, Self and Strongtalk, which was the basis for the Java VM and also the Javascript v8 VM. It’s just much easier to read and maintain. An optimized Lua with classes and a MOP, but only a simple message-passing based dispatch (type dispatch on the first arg only) and no type optimizations.
I added a lot of missing features, such as a tracing, a debugger, starts for an FFI and type system, unsafe arrays and a lot perl5 syntax support and BEGIN blocks. I could take over potion maintainance. But then eventually I got stuck with array performance, threading problems with the GC and parser problems with the GC. The threading problem with the GC is a big one, and I don’t have an idea why arrays are soo slow. This, btw, is the same problem clisp had when the nbody benchmark came up. clisp solved it, but my implementation of unsafe arrays was not good enough. And it was unsafe. You can read and write to any memory location.
What is perl11?
The Austin.pm perl mongers revived their meetings under Will Braswell, a HPC programmer (“high performance computing”). He had performance problems with his huge set of perl libaries and invited me and Ingy to meet up there. I lived in Houston then, which is next to Austin, became friends with Ingy, we got the same taste in music, and Ingy came up with the simple idea that perl5 should share more with perl6 and vice versa. 5 + 6 = 11.
It is not a very original idea, Andy Shitov and Liz Matthijssen spent big efforts to promote the idea of more interaction between those two development communities so that perl5 can eventually learn a bit or two from perl6, where all the cool things happened.
People talked about perl7 then, a fresh reboot for perl5. But of course a reboot of Perl5 as 7 is impossible this way. First you cannot run over Larry with his Perl6 efforts. Second, perl5 has no competent developers to start a perl7 effort. Nobody within p5p has any idea how a good dynamic language VM should work. Perl6 attracted a lot of those people, but the competant ones who engaged into perl5 were driven away by the p5p maintainers, who are only platform guys and perl5 programmers in this critical 2000–2003 period.
So perl11 was the best idea. Evaluate various architectures to share code, support both, 5 + 6. Ingy is a parser guy, I’m a compiler guy and then there’s the run-time and the libraries. The biggest problem is Larry’s incompatible changes to perl6 which make it impossible for a unified language, an improved perl5 with the perl6 concepts. A natural evolution of perl5 into the modern ages with a proper object and type system. But it is still our dedicated goal. So I did.
Initially we thought the missing link for perl11 is just a unified AST. Maybe it still is. But now I think it easier to add perl6 features to perl5 than using perl6/nqp as perl5 backend. The problem is that you have to know a lot about perl5 internals. The problem with the other idea, nqp as perl5 backend, is that you have to know a lot about perl5 internals AND perl6 internals. I think I’m the only one in this intersection.
The problem with blitzkost or Inline::Perl5 is that it will never be performant enough. It is a bridge to help starting over with perl6 and gradually rewrite with perl6. A bridge is always costly. But with the current perl6 model I don’t think it is practical. A perl5 can be much faster than perl6, even with its problematic OP, stack and symbol table design.
perl8.org
Stevan Little thought Scala is a better fit. For Moe, his p5-mop testground. It was a good fit for Moe, but I have a problem with that perl8.org joke. Scala is an overblown Java with slow type inference. You may get 2-3 minutes of type inference-caused compile times. It’s an unsolvable problem and you have defer certain checks from compile-time to run-time. Within the perl context perl people only talk about the parser being unsolvable. Really? We have a dynamic tokenizer and you can construct undecidable problems with dynamic prototypes, but perl5 has a very efficent parser. It’s no practical problem. Type inference on the other hand as we see with Scala or now Typed Clojure is a very practical problem. An even bigger problem than the typical JIT overhead. Why mess with that in this way?
Malcom Beattie’s perlcc—what was that?
Back in the days when p5p could still attract competent programmers they announced a competition to win a laptop for a perl compiler. Malcom studied in Oxford and wrote this compiler and the laptop 1997. First a simple bytecode compiler, similar to python .pyc files, then the simple B::C compiler which dumps the code and data structures at compile-time to a C file. Very similar to Larry’s dump code which still exists via perl -u. perl -udumps core, and then you had a little helper undump which converts this coredump file to an executable. Very similar to B::C which much less effort.
Then Malcom continued to write a real compiler B::CC which does all the possible optimizations on such a dynamic VM, which mixes strings and numbers (all three kinds) like only Basic or Javascript. B::C compiled code still runs the normal perl5 runloop with its unfortunate optree layout, which is not a good fit for a fast dynamic language. B::CC does a bit of core type inference (int and double), optree unrolling and op inlining. Unfortunately I don’t have enough time to fix the remaining B::CC bugs. But for selected modules or scripts it works fine enough and I can prototype most good optimizations with it.
Then Malcom wrote the efficient threading system, now known as 5.005 threads. Everything was shared and it was hard to avoid deadlocks. As with all his projects nobody understood it properly, and they all eventually died. 5.005 threads were replaced by safe and slow interpreter clones, which run in seperate native threads. Called ithreads. But calling them “threads” as a bit of a stretch. There’s no OP or data COW (copy on write) mechanism, no owner. Everything is copied back and forth. So fork is still the best variant to use, because this got proper COW support.
B::C appeared on CPAN in 2008. What was the purpose of it those days?
To save it. p5p was not able to maintain it anymore. They removed it from core with 5.9.5 and I thought I can. I thought it was an important and interesting piece of critical infrastructure. I always liked my lisp compilers. They were important to me and gave me the competetive advantage to do professional lisp work. So I did. I soon found out that a LISP compiler is much simplier than the perl compiler. But I still fixed it. I ported over the massive changes of 5.10 and fixed the remaining bugs over time.
Purpose? You can make your perl programs run faster and deploy easier. You can start doing business with your perl programs. I can prototype optimizations with it, and get exact benchmark numbers for proposed op.cimprovements, the internal compiler. So eventually everybody can benefit from it.
Compiler
What is the Perl compiler’s C backend?
First let’s explain a bit the terminology. The “perl compiler” contains three compilers: B::Bytecode, B::C and B::CC. Then there exists the internal perl ‘compiler’ in op.c which compiles the parsed optree to a simple linked list of OP’s with attached data, SV’s. I explained that in perlcompile.pod and perloptree.pod.
Then there exist other perl5 compilers, like perlito or an old Java backend, or the new rperl. perlito is a good framework of proper perl transpilers and compilers, which look exactly how I would have written it. The only problem is that none of the many options work good enough to compile bigger programs. rperl also uses it’s own limited parser, and maps a typed and restricted subset of the perl language to C++ stdlib classes and algorithms via Inline::CPP (C++).
Of my three perl compilers, B::C and B::CC write C files, and provide easy options to compile and link it automatically to executables. Via the perlcc frontend. perlcc by default uses B::C, with -B it compiles to Bytecode (.plc or .pmc for modules), with -O it optimizes via B::CC to compiled C files. -O is the best but has some limitations. The default perlcc with -O3, the preferred B::C option should just work, and does work fine for tons of cPanel code with perl 5.14.4 not-threaded. It passes the full perl5 core testsuite.
My pcc alias stands for perlcc -O3 -r, to compile and run any perl program with B::C on optimization level O3.
What’s the architecture of the compiler?
Let’s explain B::C, the most important compiler, which is very simple. This is the one used in production. The biggest part in a normal compiler is the parser which constructs the AST, the abstract syntax tree. We call our AST the optree. A tree of OP’s.
With my three perl compilers I don’t have do this part. Perl5 already does this in perly.y and toke.c, the tokenizer, usually called the lexer. It is very simple. perl -c stops after parsing, running all BEGIN blocks and CHECK blocks. It just quits before running the runloop in run.c. The runloop starts with the list of functions in main and then jumps into each optree of each subroutine. Every subroutine has it’s own optree, a linked list ending with NULL. perl -c just displays compile-time warnings and errors, but it also executes BEGIN and CHECK blocks. Padre users beware. Syntax checkers can be destructive with perl.
One of the excellent tricks is the O module, the compiler driver, which just calls perl -c with the given B module, a compiler or Concise or Deparse. The compiler runs through all the code and executes CHECK block hooks for all OPs and SVs, code and attached data. A typical method is called “save”. Those save methods are provided and called for all possible internal B types, which can be found while walking the optree.
So we have no parser, but a walker, which is called indirectly via data methods. It’s entirely data driven. Like in prolog. And we have those methods which convert the internal AST data to other data formats. With B::C and B::CC it is simple C code. sub B::UNOP::save is executed when the walker, B::walkoptree finds an unary op, an op with one argument. Such as e.g. negate, the minus operator with one argument. E.g. print -$a has two ops, printis a listop with avariable number of arguments, and -$a is compiled to the UNOP negate with the argument $a. You can see the names and types of all internal ops in regen/opcode.
walkoptree is called for every function it finds. The walker is a tricky part, because we don’t want to dump the compiler code itself. This is too much overhead and the compiler has too many dependencies. E.g. it has to use DynaLoader with all it dependencies to be able to override broken B methods. Tradionally p5p was never be able to properly maintain B, and even when I start to fix it, the damage was already done because I want to support every single perl release since 5.6. Why 5.6 and not a more modern perl? Because 5.6.2 perl is still the best perl around. It cannot do multibyte unicode characters, but we don’t care much about them. It is the fastest perl, the smallest perl and has the least bugs. The reason is simple: Larry was still around those days.
How is it combined with other Perl 5 code?
B::C does not combine much with other perl5 code. B::C compiles everything it finds and thinks is needed at compile-time. The rest is done in the perl5 runloop, the VM. The PP functions in libperl run the code then. A very important part is require which finds and loads other perl code and eval "", which loads other perl code. This is all done at run-time, and the compiler doesn’t need to care about it.
B::Bytecode is a bit tricker and more simplier. It uses the same trick as python does. perl5 still prefers .pmc files over .pm files with require. Those .pmc files, c stands for compiled, can be used for some shimming tricks or is just pre-compiled perl code or bytecode. So the bytecode compiler doesn’t need to decide which modules or namespaces to include and which not. It just compiles given script or module, nothing else, and the require op then automatically finds an uncompiled or compiled versions, loads the ByteLoader module, which translates the efficient bytecode via a binary source filter to perl OPs and SVs. But the bytecode compiler is not able to handle statically allocated OPs, and data. Everything has to be allocated dynamically via malloc. And nowadays malloc, dynamic memory, is the slowest part in computer programs. So the win over the parser is only marginal. There is a potential win if you compile multiple modules and scripts into a single file. Filesystem traversal to find a module is a huge startup overhead, bigger then the parsing time.
What does it produce? Is the bytecode executed by standard perl?
See above. B::C and B::CC produce C files which have to be linked with libperl to an executable.
B::Bytecode produce .plc or .pmc files, which just need the ByteLoder module at run-time.
B::Bytecode and B::C code is exececuted by standard perl. B::CC code is partially executed by standard perl and partially inlined. All the type optimizations, optimized array accesses and simple ops are inlined.
Another trick with perlcc is the new option --staticxs. This statically links all found and included XS modules to the executable. The DynaLoader step at run-time is omitted. It behaves like a static_ext perl5 module, just that it usually a shared library, not a static library. With static libraries even better. No startup overhead at all then.
The target system at the customer needs to have the same libperl library if you used a -Duseshrplib libperl.so. With a static libperl.a you won’t need even that.
With dynamic XS modules you need to provide all the used shared XS libraries to the target system. The paths prefix can be different, but with --staticxs they better should be at the same path, otherwise the system loader, ld.so, needs to find the shared library at load-time. LD\_LIBRARY\_PATH overrides or ldconfig settings are needed then. Without --staticxs the normal DynaLoader or XSLoader is used, so the XS module is searched in the system archlib path. The target machine just needs to have a proper perl setup with the same version, architecture (threaded or not, debugging or not, …) and the needed XS modules.
What is the problem with Perl’s original compiler?
perlcc is still the original compiler. There were some minor outstanding bugs, which didn’t hinder cPanel to use it for over 12 years with 5.6.2 successfully. There were some new and changed OP* and SV* data structures, but nothing dramatic. There were always B bugs, which I fixed by overriding the bad methods by my own.
B is before C, so the introspection library to support a compiler backend was named B.
Why it is not possible to integrate it back to the Perl’s core?
Because p5p is not able to maintain it. I’ll integrate it back into my variant cperl because for me it’s important to add new features to all needed places. Without perlcc/B-C in core I need typically half a year up to a year to add support for a new perl release. And sometimes as in the latest years it does not make much sense to add support for a new release, because the latest releases had other dramatic problems, the maintainers were not able to understand. At least they eventually fixed it over time. Or let’s say I had to fix it.
Language
Which features are the most difficult to implement?
New data structures and missing API’s to support static allocation of data.
Let’s take a fresh example by fatherc/sprout: PADNAME. The pad is the list if lexical variables per scope.
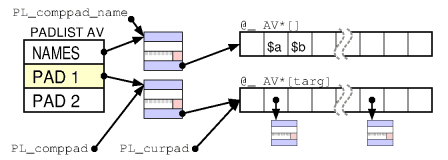
The padname was before 5.22 a PV (a string SV, SV stands for scalar value), and now just a simplier variant of it to store the name, type and static lexical index range for the compiler to find a variable in the given scope. It is not needed for run-time, only for the compiler.
Father decided that a SV for this name is too big and can be optimized a bit. He makes those decisions by his own and then commits it to master. No company would ever tolerate such a behaviour but he is a monk in greece and p5p management is a bit angry but tolerates it as long it’s not too much nonsense. And so far only his SvPROTECT/double-readonly system was pure nonsense. And he is besides davem the only remaining half-competent developer working on core. So you have to work with the remains.
Anyway, perl5 is a purely dynamic language, nobody cares about embedders or compilers, which are able to optimize much more out of data structures. There’s only the newPADNAMEpvn API to create a new PADNAME and the published/exported API supports the simple view of a PADNAME. But internally father used a good trick to store string buffers cache-friendly. He adds the variable size buffer to the struct padname via a new internal-only struct padname_with_str { char* xpadn_pv; … char xpadn_str[1]; } where [1] is dynamically used with the real length of the string buffer. This is cache friendly, no pointer indirection to the heap somewhere else. And a good C VM trick, because every PV access can be redirected statically by the C compiler because the offsets within the structs are known to the compiler. Offset 32 e.g. And the C library functions cannot handle direct string buffers char[n], you always need an indirect pointer to it.
See http://perl5.git.perl.org/perl.git/blob/HEAD:/pad.h#l86 and the PADNAME_FROM_PV() trick, which was introduced with nickc’s optimizations in 5.10 which combined the SV head with the body at compile-time.
But with the compiler I don’t want to go via the slow and only exported newPADNAMEpvn() API. Padnames and their string buffers are purely static so should be stored statically. This saves a lot of startup-time overhead and memory. Every constant string does not pressure the VMM, the OS virtual memory system, every dynamic string does. When out of memory it does not need to page out this string page. That’s why compiled perl is so much faster and smaller then interpreted perl. So I eventually have to dump different sized struct padname_with_str for each different name length, and even have to declare these structs by myself. They are not exported. So this needs at least 2-4 days of analysis and implementation to overcome this lack of API and foresight.
Thanksfully I use this same cache-friendly data trick in potion/p2, otherwise I would be still be sitting over it, figuring out what the hell he is trying to do there. Of course it is not really documented.
How do you implement the ‘eval’ keyword functionality?
Not at all. I just dump all the compile-time state, and then perl5 runs the compiled state. If it’s the same as uncompiled it will run. If there’s a difference or missing piece which I forgot to dump, eval will not work.
E.g. just last week eval was the last missing piece for 5.22 support. It eventually came out the indices for lexical variables COP_SEQ_RANGE_LOW and COP_SEQ_RANGE_HIGH moved from a PVNV to PADNAME, which is a very good change. You need those fields only with padnames (names of lexicals) when the op.c internal compiler searches for existing lexical variables. But the B API was unclear, so I added a SVf_FAKE check for those fields. Wrong. Without checking SVf_FAKE it worked ok. They added an artificial SVf_FAKE logic to B::PADNAME::FLAGS to support something else.
How difficult is it to update the compiler to follow new versions of Perl?
If you follow the development cycles for every new major release it is not much work. The problem is something else. Usually p5p is not able to come up with a proper design of a new feature, and the API is usually horrible. I am not talking about B. The normal API for XS developers and even core developers. Every new design is just horribly bad. Almost nothing would be acceptable in another language with proper SW developers and management. I have to leave out python and ruby here because they are even worse than perl5, but at least there is some kind of management going on. They have RFC’s e.g. This upsets me of course, but you are not able to critize the developers. Their manager RJBS even recently came out with the new policy to enforce “faith” into his p5p developers, because of my constant critism. If you don’t show “faith” you will be punished. perl5 has not only bless to create objects, it is now officially an religion and heretics are driven away. They don‘t show up anymore anyway.
So it usually needs some time to overcome my anger about so much stupidity and actually start implementing support for it. For example I could leave out immediate support for 5.16 to 5.20 because those releases where not worthwhile to support. But when Oleg Pronin/‘syber’ came along with his PIC patch, polymorphic inline caching to store the last used class pointer in the method with a 30% performance improvement, 5.22 suddenly became the most interesting target since 5.6.2 and 5.14.4. Of course p5p managed to talk Oleg down to throw away the PIC advantages and only use a naive monomorphic inline cache, i.e. store no hash of classes, just the last used class, but it is still a monumental improvement for method calls. “Why do we need a third hash implementation?” People should really be more critical and either use the older properly maintained versions or don’t let p5p get away with technical nonsense. They usually have no idea what they are talking about, most normal CPAN developers do know better.
Team
How many people work on the project?
We do “Scrum” with a team of seven. Three-four devs plus the rest. But I do this teamwork stuff only when a new compiler release comes close. This involves a lot of testing and a lot of burned CPU times and a lot of compiler related or user-related bugs. So having a team is fantastic.
How do you communicate?
Via public code and commit messages, github/jira comments and tickets. My work is usually in the public, I only held back cperl for a while. Late in a release cycle I go to the daily standups, which should last 10 minutes, but in my case usually last one hour, because my folks want to understand why I did this and that. This is not really “agile” nor a standup anymore, but they need to fight the busfactor, to get a proper understanding what I’m doing and how I’m doing it. This is now usually via GotoMeeting screensharing, and management talk is via video conferencing (Google Hangout or Hipchat). Internally we switched from gitorious to Jira/Stash, which is a much better system than github. I did chose originally google code for the public repo, even if it was much worse than github. I thought Google as huge company will keep it longer stable than github, and I was sceptical how long github will survive. I was wrong, and I had to move over all my tickets from googlecode to github. Some are still lost, and the numbers changed. Horrible. I’ll never trust google and this “too big to fail” argument again.
Nowadays as remote worker I visit the company four times a year and we meet at conferences. When I’m not too fed up to go to conferences at all. It’s a high burnout risc.
How do you decisions?
Mostly I do work on my own and do make my own decisions. cPanel early on decided that I don’t need to be managed. Which was a good decision 🙂 Experienced developers can manage themselves better and managers are there to help.
Sometimes others question my decisions. Then I have to argue with them. This costs a lot of time, but they need to understand it eventually. So it is fair.
I don’t believe in design by commitee, I used to work with the Common Lisp elephant. There’s a point in doing the lisp way, i.e. doing it by yourself, alone. See Paul Graham’s Revenge of the Nerds and esp. Dick Gabriel’s The Evolution of Lisp But I do appreciate criticsm.
Beyond Perl 5
You said it is now more “like Perl 6” – what does that mean?
I guess you mean my new cperl variant, which I just announced at the YAPC EU 2015 in Granada.
Traditionally perl6 was the testing ground for new perl5 features. Unfortunately Larry deviated the syntax too much, but the concepts were proper perl concepts which could be implemented on top of perl5 as on perl6. Traditionally perl5 completely failed to properly implement any new perl6 feature. Only the simpliest made it, say. But I can tell you that with 5.005 threaded code even say is wrong as we found out later with parrot. Given/when, smartmatch, switch, signatures, lexical subs, pseudohash, native threads, cow, double-readonly, lexical warnings, refalias all were horrible failures, and nothing was done for anonymous classes, readonly-ness or a proper COW, not even talking about dispatch, types, OO. So p5p became very defensive and added experimental and feature to mark those new features as a potential failure and hinder its wider usage. It’s a protection from potential failure.
The new shorter release cycle came from perl6 on pressure by chromatic. I’m not sold on it, because it looks like perl5 makes steady progress but it makes sense business wise. Some Porting tools and tests came from perl6, but it’s still far behind. Most perl6 advantages over perl5 were never introduced.
Now talking about perl6 features in perl5, my cperl variant. Besides having to revert perl5 breakage from time to time, and add missing support for easier and more performant compilation my plan with cperl is to overcome the development deadlock in p5p. They dont allow significant features to be added to core, only if you are a committer. And unfortunately those committers do more damage than good. So I decided come up with this variant cperl, a perl5 with classes, where I can add the needed optimizations and features any normal self-respecting dynamic language does have. So I can add many Perl 6 based features, but without breaking compatibility and without having resort to external modules. It is not possible and not a good idea to come up with modules for the most basic language features, even if the module idea would benefit older perls also.
cperl is a ‘perl 11’, 5 + 6 = 11.
The name cperl stands for a perl with classes, types, compiler support, or just a company-friendly perl, but currently it’s only a better 5.22 based variant without classes. Currently it is only about 1.5x faster than perl5.22 overall, more than 2x faster then 5.14 and uses the least amount of memory measured since 5.6, i.e. less than 5.10 and 5.6.2, which were the previous leaders. While perl5.22 uses the most memory yet measured.
But most important: CPAN works. We already known that perl5 works not good enough, but that’s what we have. With p2 I wanted to break CPAN and offer a good FFI instead, which was not a good idea.
With my signatures being added soon, it’s about 2x faster with the potential of much bigger improvements with typed modules. Native types, native shaped arrays, and especially inlined functions and methods and unrolled loops it will become much faster.
When perl6 was born, nobody was able to improve perl5, nobody wanted to do that. Today this is still the same, but at least I try to work on improving the perl5 VM. The old argument was that perl5 is horrible and not maintainable, but this argument is wrong. Larry is an excellent hacker and most of the things he said made sense. Only when he left and p5p took over the codebase it became worse and worse.
Scalars still suck, don’t get me started on that. They got much better, but are still horrible. Compare that to normal “primitives” in dynamic languages. There a scalar is one word, and when blessed as in Common Lisp two words. Our shortest are 4 words and a string uses 10 words plus the buffer. You cannot do simple lvalue work on the stack with 4 words.
Arrays do have at least a proper unshift optimization, but cannot store static arrays, cannot hoist out of bounds checks from run-time to compile-time, cannot properly deal with multiple dimensions and cannot store native types. Which would be much faster, smaller and overcome the lvalue problem. I solved most of that already, just not the static part yet.
Hashes are even worse, I cannot say a good word about perl5 hashes at all. See my perl-hash-stats for the problems, and I started with small various attempts to fix it step by step. Abstract bucket search. Move to front. Use a better load factor. Support pointers. Better HEK layout to be cache friendlier and support a faster inner search loop. But overall not possible. I have to rewrite them completely.
Symbols: Just a nested hash of hashes, jumping from one namespace into the next, not one global optimized datastructure to search prefixes efficiently? Really? Adding \0 and unicode, really? This is pure nonsense. With a pure ASCII symboltable a patricia tree would have made sense, but there are many good options. Any global dictionary with iteration support for common prefixes should do. Worse, Symbols cannot be initialized statically, because they always free unconditionally. This is actually my biggest compiler problem. Having to initialize all these global symbols at init-time is comparable to bad and bloated javascript usage in webpages.
Objects: We have a nice mop by different representions of blessed data. But as we saw it was not a good thing. OO was never performant enough, and the most basic OO feature were never implemented. Mixins were added in a unperformant hack, while the whole idea of mixins are compile-time optimizations. Multiple dispatch is not implemented, you still have to use overload or naively implemented libraries, with no multiple dispatch support, because there are still no types in signatures.
Functions: Huge call overhead. Not usable for library functions, so internally perl uses ops for most library calls! No method call optimizations besides MIC (monomorphic inline caching). No inlining, the most important language implementation feature. No macros, unevaluated arguments. No signatures, well they are in but a joke. No types, but this is tricky I admit. No multi dispatch, leading to poor OO. My function calls were 200x faster in p2, using a proper calling convention.
Classes: Don’t exist. Various variants exist, but none of them is good enough for any self-respecting language. Just look at what PHP did there recently. Proper design and proper implementation.
But the biggest problem: The not existing management. Management is done via marketing only, but not by helping the devs, helping the project and helping the users. We really need a technical lead, not a community lead. Why do we need a community pumpkin who finds out that someone finally implemented bind my $a := $b;, but with the interesting name refaliasing and the syntax \my $a = $b; and could do nothing about it. Marketing jumped on and declared it as “It’s cleaner, safer, and faster.” schmorp called them clowns. He is right.
And the destructive elements are on its rise. Indirect method calls are currently in danger with 5.24. They cannot explain to the poor user that the parser is dynamic, that perl is a dynamic language. After decades of defending dynamicsm over gradual typing they suddenly announce to favor static dispatch only. It makes sense in a business environment, yes, but not for normal perl script usage.
my $file = new File $path, $data
save $file;See http://perl5.git.perl.org/perl.git/blob/HEAD:/pod/perlobj.pod#l685: “Outside of the file handle case, use of this syntax is discouraged as it can confuse the Perl interpreter” (clearly only p5p is confused about that) vs my variant: “Indirect Object Syntax resolves the syntax dynamically.”
Parrot had a very similar history to perl5. When the competent authors left after heavy infighting the inmates took over the asylum and ran it into the ground.
Now to the perl6 coincidences. Interestingly, when I started working on cperl, perl6 was at about the same stage with their features. Just they could do it in perl6 or nqp, I did it in C. I added my native types, when they added theirs. I added my shaped arrays and native arrays, when they added theirs. I skipped the uni and Uni part, efficient representation of unicode strings, and my type inferencer is primitive and does not work for user functions yet. They already have a proper OO system. I’m still on the design of class and multi methods. But when looking how it should be implemented I rather look at how the good VM’s solved it, such as self/smalltalk/strongtalk/potion or lisp based VM’s, and only rarely look over to the perl6 implementation. A C implementation usually makes more sense to me.
Can it be modified to compile Perl 6?
No, of course not. I don’t care much about perl6 the VM and the language. I do care about improving perl5 based on perl6 syntax decisions. Previously I did care about perl6 when I finally could start to fix and improve parrot. And I cared about a perl6 VM with potion/p2. But then I cared more for a unified VM for both, a unified perl11. Only a subset of perl6 which is relevant to perl5, and eventually support for multiple syntax blocks within the same program. Which I did implement in a performant way, not the HLL hack as used in perl6 or parrot.
But nowadays I don’t care that much anymore. I consider the rakudo architecture not practical. It is not possible to get out of the current bootstrapping hell and it is not possible to properly support concurrency with blocking all over. Problems are solved again on the library level, and there’s no concept of ownership in the vm. Only parrot supported that. Similar to rust. But parrot lacked a lot of other stuff the old maintainers removed or destroyed. parrot was an even worse minefield then p5p. And I’m happy that I stayed out of this debacle. I resigned with 1.0. And when they eventually burned out I could come back and fix some critical parts. But as history showed it didn’t help and it was not enough.
Current results
What are the advantages of switching to the new compiler?
cperl is not a compiler. It is a perl5 variant with improved internal compiler optimizations. It is maintained differently. It adds a lot of internal improvements, the biggest improvements perl5 had in the last 10 years. It is not plagued by p5p hell and there’s a clear way to go forward. See cperl/STATUS.
The busfactor is better, +1 with cperl vs -2 with perl5.
The disadvantages are: Less eyes, less platform tests.
Is it important for small companies?
Currently cperl is not important at all. I just had to rush out a premature 5.22.1 release without many important features. I planned to release it much later. The features in the branches I’m working on will make it very attractive. Esp. when I finish inlining, native types and add class and multi method support. Then you will be able to use a proper and performant object system and get rid of Moose finally. perl5 did too much damage in the last decades to object systems already.
Small companies need to rely on stable infrastructure and libraries, hence the importance of CPAN support. And eventually fast concurrency support. Which is not solved with cperl. Maybe with Coro+EV (fast context switching, lua style), or maybe via native threads (perl6 style). But I’m not too enthusiastic about perl6’ future with rakudo. But as you all know, worse is better. The slowest languages with the biggest feature set win.
Officially there is dead silence, but I hear from very big companies, bigger than cPanel which is the biggest perl-only company nowadays, that they are discussing cperl a lot. Let’s see.
In the meantime my colleagues will try to backport most of my >1000 patches to p5p. Good luck with that 🙂
What about support in the future?
I don’t know. There is a high risc of burnout because of the ongoing self-destruction in p5p. And there’s a small risc that I switch back to a proper language with likewise maintainers, or different projects eventually. When AutoCAD dropped lisp development in which I was heavily involved internally, I got fed up with lisp. I did perl for fun, and php for work. But even during my perl5 phase with Inode in the early 2000 years I did much more php than perl5, and after that I worked in Formula 1 on much more complicated and advanced real-time systems then my perl projects. I only came back to 100% perl because my river surf wave in Graz was on the brink of destruction, which got me so angry that I had to leave the country. So I married, took cPanel’s attractive offer and moved to Texas working on the compiler. Which was very successful. After the US buerocracy was not able to prolong my H1-B visa in time I moved to Dresden, but can I work remote, which is even better than working in Texas.
Mostly it depends on cPanel. Currently they are sceptical, because cperl had not enough eyes. We will see.
On the positive side, I’m the only known perl5 developer who is properly paid 100% to work on perl5 core full-time. There are some which work is funded to work half-time on it, but we saw what became out of that. It’s called maintenance work, which is a proper name. But not a single p5p success story since 2002, besides //=, and lot of damage done. And now I was finally able to start working on perl5 core itself. I was held back for years. I had to stablize the compiler, wanted to save perl6. I’ll try to make the best out of it.
Platform support is done via the perl5 porters. They are the experts for platform problems and maintainance. I’m the expert for the compiler and the VM.
And I’ll have to setup my git rebase workflow for tracking blead also. I started with git rerere support to automatically and easily rebase my work branches, but haven’t setup this for blead rebases yet. I could easily give a 1hr talk at a conference how to efficiently maintain a fork with git. I did this for openssl/libressl and for perl5/cperl without any pain for half a year. Almost fully automatic. With cperl I did the blead merges monthly but after reading google’s statements on this, I’m now convinced that only immediate rebases and merges do make sense. Same as Gerard Goossen did with kurila using Sam Vilain’s scripts, but he didn’t have git rerere then.